Exploring British Accents: Modeling the Trap-Bath Split with Functional Data Analysis
Abstract
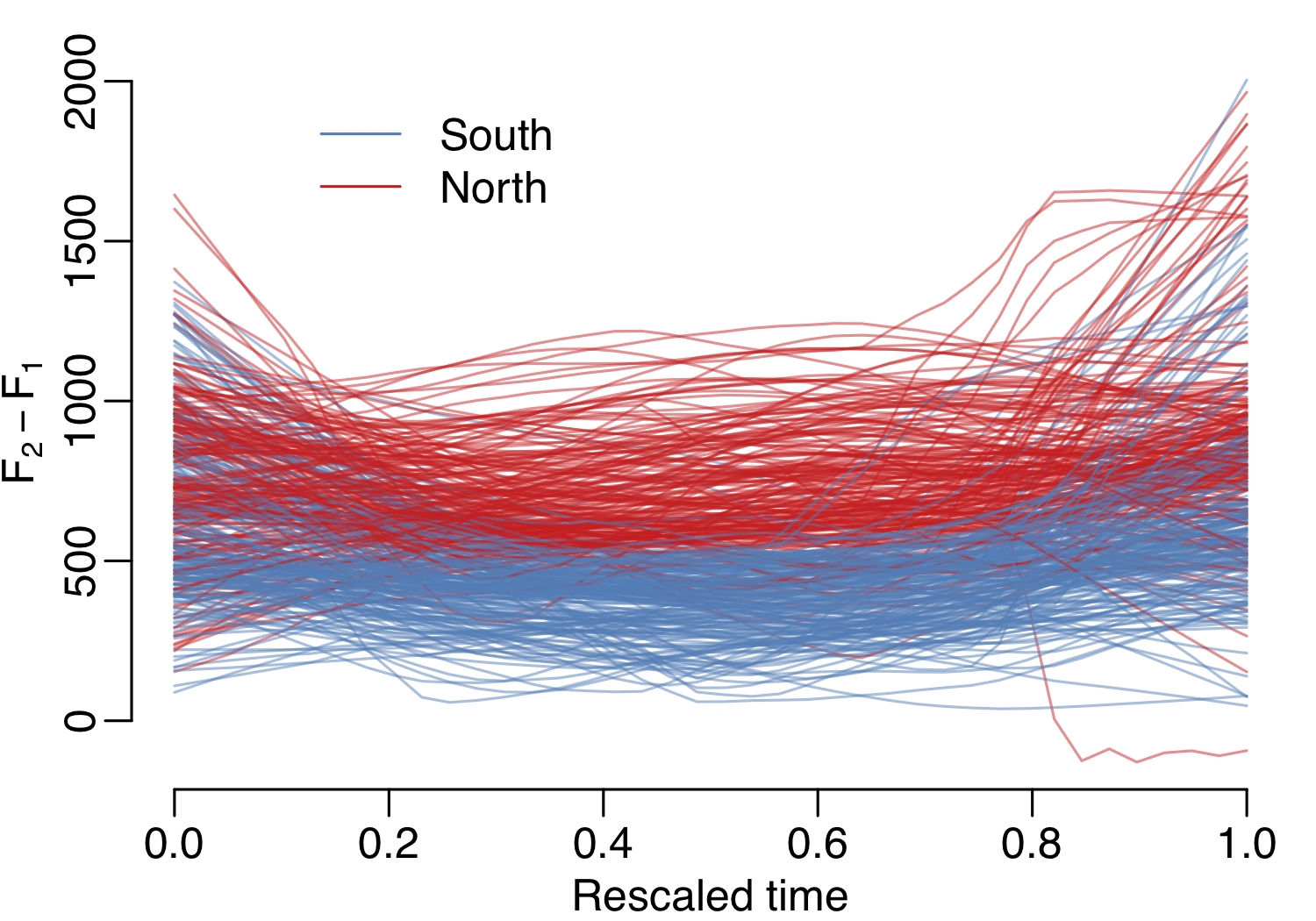
The sound of our speech is influenced by the places we come from. Great Britain contains a wide variety of distinctive accents which are of interest to linguistics. In particular, the ‘a’ vowel in words like ‘class’ is pronounced differently in the North and the South. Speech recordings of this vowel can be represented as formant curves or as Mel-frequency cepstral coefficient curves. Functional data analysis and generalized additive models offer techniques to model the variation in these curves. Our first aim is to model the difference between typical Northern and Southern vowels, by training two classifiers on the North-South Class Vowels dataset collected for this paper (Koshy 2020). Our second aim is to visualize geographical variation of accents in Great Britain. For this we use speech recordings from a second dataset, the British National Corpus (BNC) audio edition (Coleman et al. 2012). The trained models are used to predict the accent of speakers in the BNC, and then we model the geographical patterns in these predictions using a soap film smoother. This work demonstrates a flexible and interpretable approach to modeling phonetic accent variation in speech recordings.